
运维
程序人生
defer
nginx
广域网
uni-app
html静态网页制作
进程替换
IT难
魔百盒固件
cloudera
数字化转型
视频
飞机大战
发sci
金仓数据库
爬山算法
模块测试
知识产权
junit
读高性能MySQL(第4版)笔记04_操作系统和硬件优化
相关文章

vue2中的列表渲染v-for
一、定义
⽤ v-for 指令基于⼀个数组来渲染⼀个列表。 v-for 指令需要使⽤ item in items 形式的特殊语法,其中 items 是源数据数组,⽽ item 则是被迭代的数组元素的别名。
二、 遍历数组
2.1 写法
<li v-for"(item,index) in list">…
JS篇章高频面试题【2023】
JS篇章 JS由那三部分组成? ECMAScript是JavaScript的核心,定义了语言的基础特性,如变量、函数、数组、对象等。 DOM文档对象模型提供了可以让开发者操作网页上的元素和它们的行为。如点击按钮等。 BOM浏览器对象模型提供了与浏览器交互的方式…
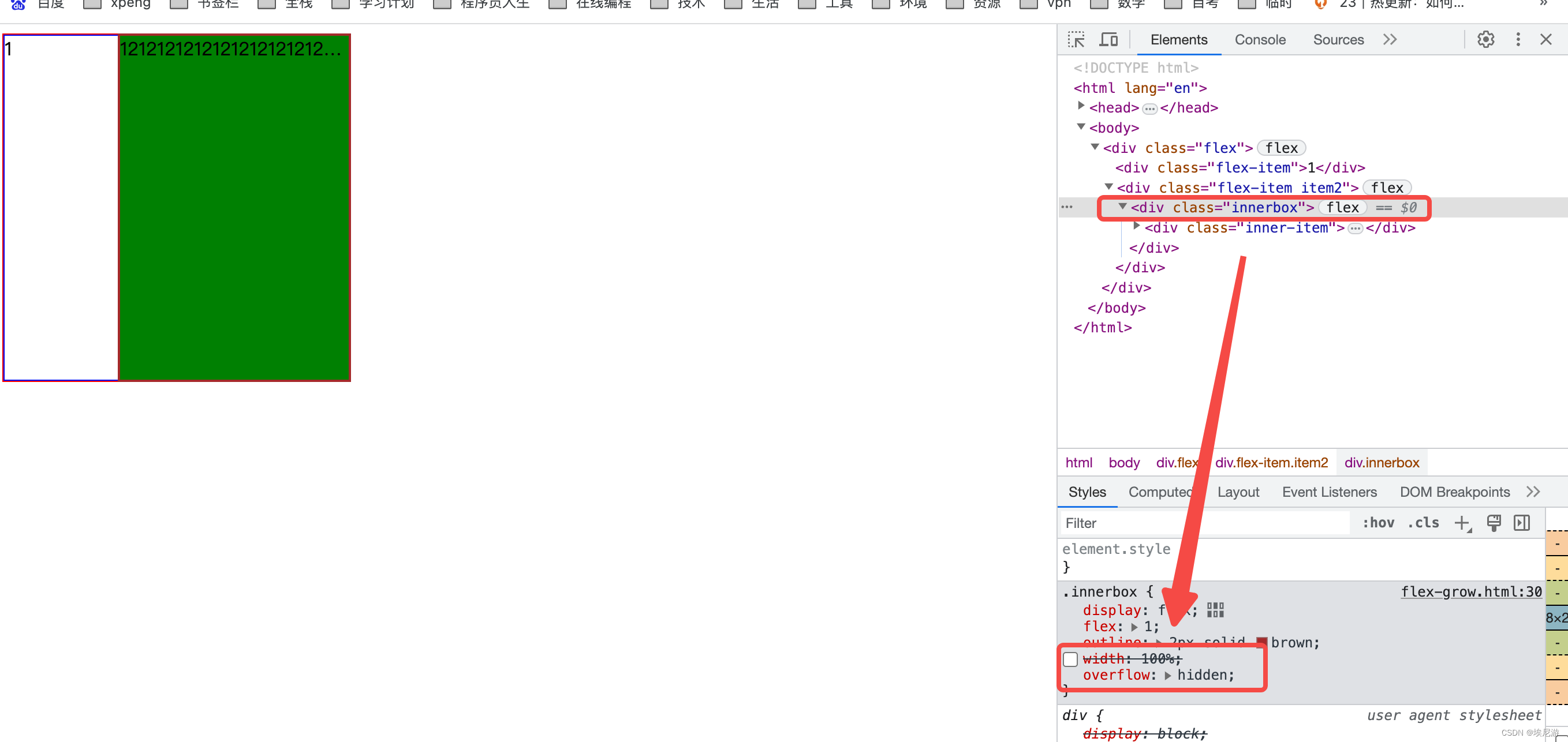
css flex:1;详解,配合demo效果解答
前言
给设置了display:flex的子组件设置了flex:1;就能让他填满整个容器,如果有多个就平均
flex:1;是另外三个样式属性的简写,等同
flex-grow: 0;
flex-shrink: 1;
flex-basis: auto;我们就针…

在 Windows 上远程对 Linux 进行抓包
文章目录 名词解释事先准备下载安装 Wireshark下载运行 libpcap设置 libpcap 环境变量在 Wireshark 中远程连接 libpcap 笔者的运行环境:(成功) 本地客户端: Windows: Windows 10 教育版(本文) …
LA@二次型@标准化相关原理和方法
文章目录 标准化方法正交变换法🎈求矩阵的特征值求各特征值对应的线性无关特征向量组正交化各个向量组 配方法步骤例例 初等变换法原理总结初等变换法的步骤例 标准化方法
正交变换法🎈 二次型可标准化定理的证明过程给出使用二次型标准化的步骤 该方法…

祝贺!Databend Cloud 入驻 AWS 云市场
关于 Databend Cloud
Databend Cloud 是基于开源云原生数仓项目 Databend 打造的一款易用、低成本、高性能的新一代大数据分析平台,提供一站式 SaaS 服务,免运维、开箱即用。
Databend Cloud 架构如下: 存储层完全面向对象存储而设计。 计算…
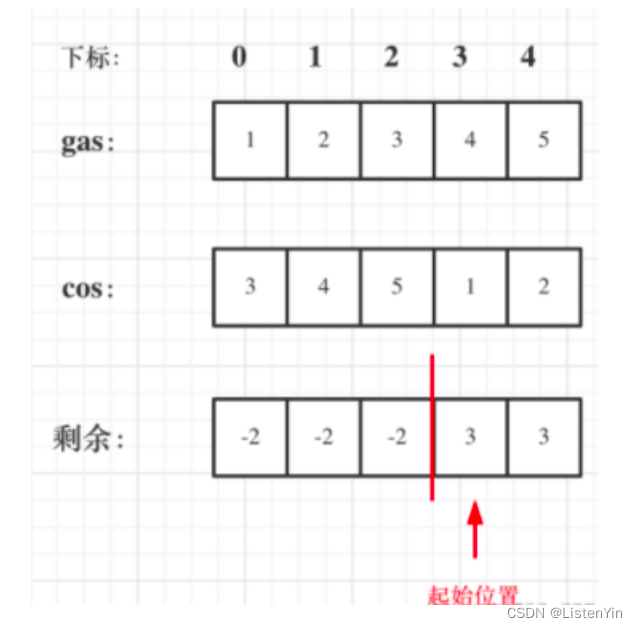
算法通关村第十七关:白银挑战-贪心高频问题
白银挑战-贪心高频问题
1. 区间问题
所有的区间问题,参考下面这张图 1.1 判断区间是否重叠
LeetCode252 https://leetcode.cn/problems/meeting-rooms/
思路分析
因为一个人在同一时刻只能参加一个会议,因此题目的本质是判断是否存在重叠区间
将区…
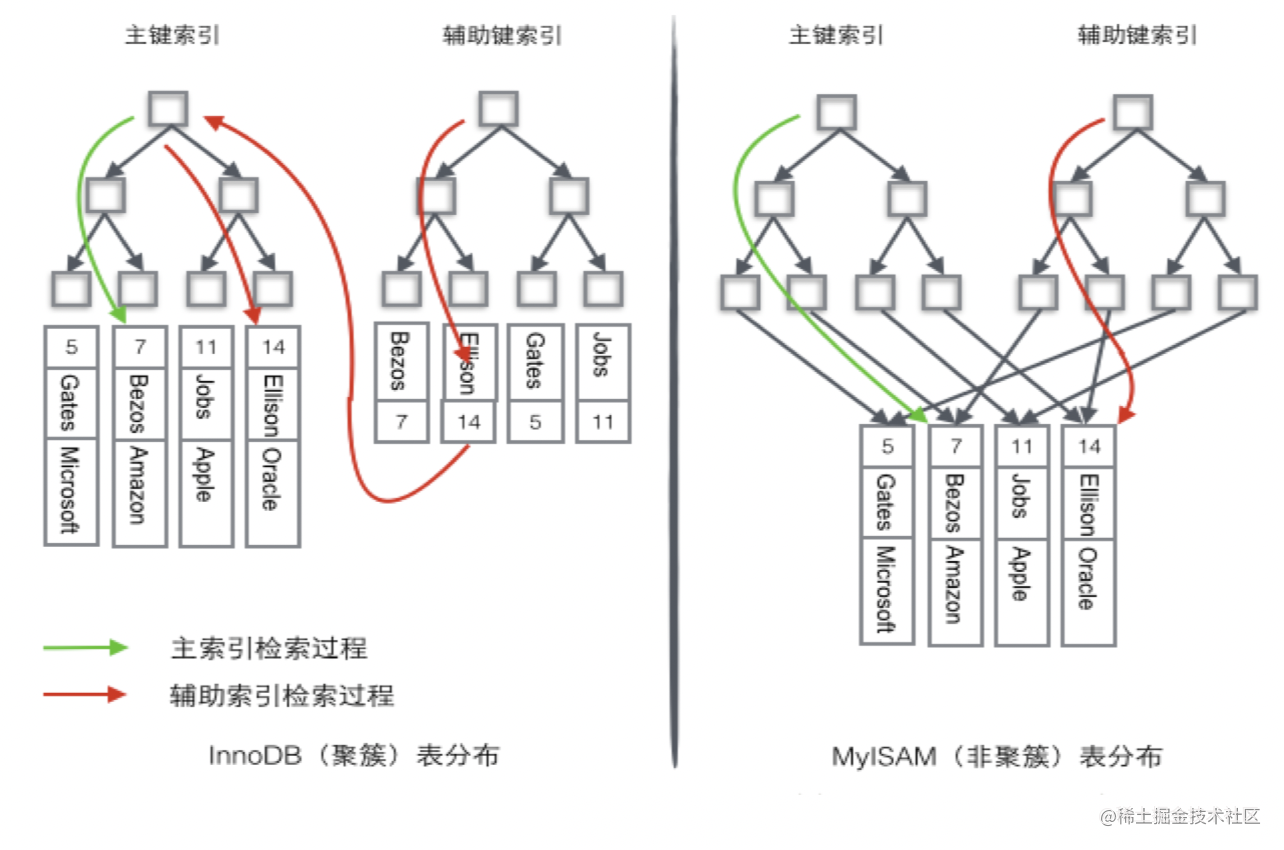
MySQL聚簇索引与非聚簇索引
分析&回答
当数据库一条记录里包含多个字段时,一棵B树就只能存储主键,如果检索的是非主键字段,则主键索引失去作用,变成顺序查找了。这时应该在第二个要检索的列上建立第二套索引。这个索引由独立的B树来组织。有两种常见的方…